
原文链接:https://www.bilibili.com/read/cv16730942
阅前须知:
alexair059@gmail.com
什么是Disco Diffusion?
Disco Diffusion (DD) 是一款可在 ,它利用称为 CLIP-Guided Diffusion 的 AI 图像生成技术,允许您仅从文本输入中创建引人入胜的精美图像。 DD由 创建,由 增强,并以 、 和许多其他人的工作为基础。
免费


DD的运作过程(简单概述)
扩散是从图像中去除噪声的数学过程,而CLIP 是用于标记图像的工具。 结合使用时,CLIP 使用其图像识别技术迭代地引导扩散去噪过程,使图像的内容逐渐与文本提示的概念紧密匹配。
上面的图片[1]便是在 DD 中仅使用“提示”创建的,其内容为:“A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation.”
扩散是一个迭代的过程。 在每次迭代/步骤中,CLIP 都会根据“提示”评估现有图像,并为扩散过程提供“方向”。 扩散将对现有图像进行“去噪”,而 DD 将显示其对最终图像外观的“当前估计”。 最初,图像只是一团模糊混乱的噪点,但随着 DD 迭代的推进,图像的细节从逐渐由粗略变为精细。

上面的示例图像[2]生成总共耗费了250次扩散迭代。正如您看到的那样,随着 CLIP 根据“提示”不断引导扩散降噪过程,图像在该过程中逐渐变得清晰。
图像的内容通常由“提示”——句子、短语和一系列描述性词语(译者注:甚至是网络关键词和艺术家!例如trending on artstation——artstation上的热搜、Miyazaki Hayao——宫崎骏)控制,这些词语告诉 CLIP 您想看到什么。
为 AI 艺术创建一个好的“提示”是一项细致入微、具有挑战性的任务,需要大量的反复试验和实践。 它需要您琢磨学习,但本指南不会详细介绍。 我们侧重于介绍如何调整Disco Diffusion该jupyter文件的基本参数。
DD 的大部分控制参数需要填写具体数字,以控制 CLIP 模型和扩散曲线的各个方面。使用 DD 的一般流程是:
-
-
调整控制参数
-
根据使用的设置和可用的处理器不同,DD 渲染单个图像的时间从 5 分钟到一个小时不等,甚至更长时间
微调“提示”和控制参数既复杂又耗时,因此不断去尝试并形成自己的一套技巧会更好。 我们建议您先尝试一下jupyter文件中的默认设置,以确认文件运行正常并且您的设置没有错误。 在那之后,尽情地实践你的点子吧!
此外,尽管 DD 支持生成整个作画过程的动画,您仍应该从学习如何创建静止图像开始,因为学会创建图像后生成动画将十分简单。
用AI(Artificial Intelligence/人工智能)创造艺术是神奇而复杂的,数据科学家和程序员在该领域的研究从未停止。因此,如果一点点努力与专注都不屑于付出的话,你同样可能毫无收获。DD有几十个控件,交互复杂,限制少,很容易得到不好的结果。 但不要气馁!
请记住,您并不孤单。成千上万的人正在学习和学习 AI 艺术,并且有许多资源可以与其他 DD 用户和 AI 艺术家联系并向他们学习。例如有一个专门的 、一个 和twitter 上一个活跃的用户社区。 还有几十个很棒的 Youtube 和书面教程和指南。本指南末尾包含相关的资源链接。
The harder the climb, the better the view!
祝您画出心目中的佳作!
March 2022
Chris Allen ( on twitter)
p.s. 我希望本指南将成为 DD 用户的有用起点和参考。但这并不代表它是绝对正确的!
虽然我试图通过询问一些实际的 DD 开发人员和相关专家来进一步了解DD,但该文档目前的所有内容都是我个人未经严格证明的见解。
尽管尽了最大努力,但本指南依旧充满了可能的错误。这是个人的能力问题,我只是不知道它们在哪里。我也是AI艺术的学生,一起学习吧!
如果你看到错误或错误信息,对我的无知感到可笑之后,请在推特上发表评论,或者在 DD Discord 上直接戳我!
使用Disco Diffusion(DD)- 基础设置
Disco Diffusion (DD)(当前版本为 5.2)起初令人望而生畏且难以理解。但只要一点点学习,你最终就能完全理解。
本指南假设您了解使用 Google 的 Colab 服务访问和运行jupyter文件的基础知识。如果您并不了解,请先查看附录中的一些推荐资源以进行学习。
判断 Colab 正常运行
当您在 Colab 中启动 DD 笔记本时,它已经设置了默认值,将生成像上面那样的灯塔图像[1]。在更改任何设置之前,您应该只运行所有代码 (代码执行程序\全部运行) 以确认一切正常。Colab 将提示您授权连接到您的 google 云端硬盘,允许该操作以使 DD 正常工作。
之后,DD 会花数分钟设置环境,最终会在笔记本最底部显示正在生成的扩散图像。 一旦您确认所有这些都正常工作,您可以随时中断程序(代码执行程序\中断执行)。
快速上手 – 使用默认参数
初始设置后,您就可以开始创建自己的图像了!DD有很多选项,但如果您只想输入提示并使用默认设置生成图像:
-
-
鼠标滚动到jupyter文件接近底部附近的 Prompts 单元格。请注意已经存在的示例的语法,用您自己想描述的“提示”替换相应的句子
-
单击 Prompts 单元格的运行按钮,这将更新下一次运行的“提示”
-
在 Prompts 单元格下方,即 4. Diffuse! 下,展开单元格并将 display_rate 值从 50 更新为 5
-
单击 Do the Run! 旁边的运行按钮
-
大功告成!您现在正在自己提供“提示”创建自己的图像!
您可能喜欢或不喜欢您的第一张 DD 图像,但如果您想让它们变得更好,请继续阅读该指南吧!
文本提示词 / “提示”
首先便是大家最关心的文本提示词,又称“提示” —— 输入文字描述并得到对应图片。
在 DD 中,文本提示词的设置在jupyter文件靠底部的地方。“提示”可以是几个词、一个长句子或几句话。编写“提示”本身就大有学问,这里不会涉及,但 DD 提示部分有一些示例与所需的格式。
text_prompts:描述图像应该是什么样子的短语、句子或单词和短语字符串。人工智能将分析这些单词,并将引导扩散过程朝着靠近描述的方向上优化。
E.g. “A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation.”
文本提示词大致遵循这样一个结构:[主题]、[介词细节]、[设置]、[基本修饰和艺术家];这是您尝试的一个很好的起点。
(译者注:
-
主题[subject]:画面的主体对象如一座城堡
-
介词细节[prepositional details]:主体所处环境如花海当中的一座城堡
-
设置[setting]:主体对象的活动或状态如花海当中举办盛大庆典/逐渐荒凉凋敝的一座城堡以及其具体修饰如花海当中逐渐荒凉凋敝的一座巨大的/英式城堡
-
基本修饰[meta modifiers]:提示DD该图像的艺术风格、或传达的情感如一种伤感的风格、胶卷相机拍照的风格、抽象风格
-
艺术家/创作者[artist]:提示DD该图像类似于某个具体创作者的风格如宫崎骏、梵高、莫奈
)
不断获得可靠的文本提示词需要实践和经验,但它不是本指南的重点。如果您第一次接触该事物,那么在使用 DD 之前,一个简单的 AI 艺术应用程序(如 、 或 )是一个不错的起点,您可以逐步了解 GAN 工具如何将文本转换为图像。这些其他应用程序使用的技术可能不完全相同,但也同样有许多相同的原则适用。
image_prompts:图像提示词是引导扩散过程朝向特定外观或风格的另一种方式。但是,使用图像提示词是创建其他图像的一种间接方法,并且不如文本提示词可靠。
进阶——文本提示词权重 & 动画帧
您可以只使用单个文本提示词、即只用一段文字描述一批图像或动画。不过DD 在该部分允许您进行更细致的调整。
DD 在jupyter文件中的 Prompts 单元格部分具体可分为动画帧号和字符串列表。字符串列表包含了指导DD在扩散过程中的各个文本提示词。字符串的结尾可以包含一个 “:” + 数字来指示该提示词相对于其他提示词的权重。
每个提示对推动扩散方向的相对贡献是其权重除以所有权重的总和。权重可以是负数!负权重可以帮助抑制不需要的提示匹配的特征,例如文本、水印等等。例如 0:[“rocky beach:2”, “sky:-1”] 引导图像扩散偏向岩石海滩细节,同时减弱天空细节。注意:权重之和不得等于 0!
行首的数字是动画帧号。如果使用动画,可以通过添加更多行不同动画帧的提示随时间改变提示,DD会在指定帧切换文本提示词。注意:以这种方式添加多个提示仅适用于动画!(译者注:DD创作动画的可能性?动画帧连起来就是剧本~)如果您正在运行一批单独的图像,DD 将只使用第一个动画帧下的文本提示词。
基本设置
准备好文本提示词/图像提示词后,您需要在 Basic Settings 单元格设置该次图像创作的名称(译者注:默认为TimeToDisco),你也可以调整一些相关的参数。这些参数是控制 DD 图像特征和质量的核心,有些参数与其他参数的作用会相互影响甚至抵消,这使得 DD 成为一个丰富而复杂的工具,需要一段时间来完全掌握。
对于某些参数,您会在旁边看到数字。例如 (250|50-10000) 分别表示 DD 的默认值以及常用范围。
这些默认值和范围大部分情况下具有参考意义,但绝不是硬性限制。DD仍在不断进步中。一些用户正在积极进行“参数研究”(参见资源附录)以可视化参数的工作范围以及与其他参数的交互。因此,一旦您对每个参数感到满意,您完全可以尝试更极端的值(包括负数),以找到最适合您的艺术目标的值。
batch_name:批处理、即该次创作图像的文件和文件夹名称。最终图像/视频将保存在 \My Drive\AI\Disco_Diffusion\images_out\batch_name下
width_height:(默认为[1280,768] 受 VRAM 即显卡内存限制)所需的最终图像大小,以像素为单位。你可以有一个正方形、宽或高的图像,但每个边缘长度应设置为 64 像素的倍数,并且在默认 CLIP 模型设置上至少为 512 像素。如果您忘记在尺寸中使用 64 像素的倍数,DD 将自动调整图像的尺寸。
注意:在 Colab 上,[512×768] 是中等图像,这是一个不错的选择。[1024×768] 会被视为大图像,可能会导致 OOM(内存不足)报错。
设置更大的宽高将使用更多的内存,可能会导致 DD 崩溃。所以建议首先从小处着手。如果你想要一个非常大的最终图像,一种常见的做法是使用 DD 生成中等大小的图像,然后使用单独的 AI 图像放大器来增加 DD 生成的图像的尺寸。
一个有趣的 CLIP-Diffusion 现象:如果您将图像的尺寸设置得非常高(即 512 x 1024),那么对于高大/巨大的“提示”,您可以获得更好的结果;例如 “A giant creature.” 同样宽幅图像也可用于全景风景等宽幅主题。这可能是由于用于训练各种 CLIP 数据集的原始图像的方向和格式对其产生了影响。
steps: (250|50-10000 迭代次数) 在创建图像时,整个扩散过程迭代地进行处理。每个步骤(或迭代)都涉及 AI 查看称为“剪切”的图像子集,并计算应引导图像的“方向”,使其更符合“提示”。然后它在扩散降噪器的帮助下调整图像,并进入下一步。
增加迭代次数将为 AI 提供更多调整图像的机会,并且每次调整的幅度都会更小,从而产生更精确、更详细的图像。但增加迭代次数意味着更长的渲染时间。此外,虽然增加迭代次数通常会提高图像质量,但超过 250 – 500 步的额外步数的回报会递减。然而,一些复杂的图像可能需要 1000 步、2000 步或更多步。一切取决于你自己。
总之关于迭代次数最重要的是渲染时间与步数直接相关,许多其他参数对图像质量虽然同样有影响,而无需花费额外的时间。
skip_steps: (10|integer up to steps) 如下图所示[3]。噪声调度(降噪强度)开始时非常高,随着扩散步骤的进行逐渐降低。由于前几个步骤的噪声水平非常高,因此图像在早期步骤中会发生巨大变化。
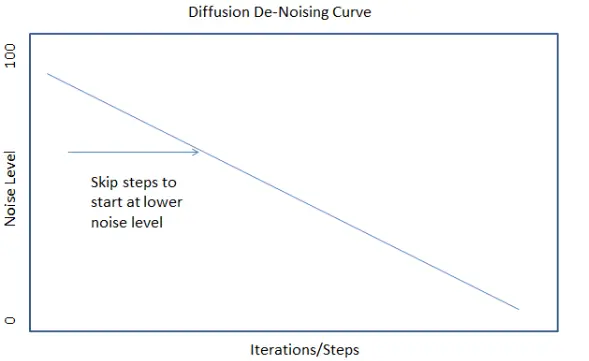
随着 DD 沿着曲线移动,噪声水平(图像每一步相关的变化量)开始下降,并且从一个步骤到下一个步骤的图像相干性增加。
去噪的前几次迭代通常非常跳脱,以至于可以跳过他们(可能是总迭代数目的 10-15%)而不会影响最终图像。您可以尝试使用此方法来缩短渲染时间。
但是,如果您跳过太多次迭代,剩余的噪声可能不足以生成新内容,因此可能没有“剩余时间”来令人满意地完成图像。
此外,根据您的其他设置,您可能需要 skip_steps 以防止 CLIP 过度拟合,导致颜色“溢出”(过饱和、纯白色或纯黑色区域)或其他较差的图像质量。鉴于去噪过程在早期迭代优化时最强,因此恰当地跳过有时可以缓解其他问题。
最后,如果使用 init_image,您将需要跳过大约 50% 的迭代次数以保留原始 init 图像中的形状。
但同样有趣的是:使用低skip_steps,您可以获得“灵感来自” init_image 的结果,它将保留颜色和粗略的布局和形状,但看起来完全不同,看上去就好像某人从init_image 中获得了灵感一样。如果使用高 skip_steps,您可以保留大部分 init_image 内容,只需对纹理进行微调,看上去就好像保留了init_image的绝大部分构图与思路,仅仅是细节的更改。因此,如果您使用的是 init_image,您也可以试着向上或向下调整 skip_steps。(译者注:毕竟zippy自己也说过指南不一定是完全正确嘛~)
clip_guidance_scale:(5000|1500-100000) CGS 是您将使用的最重要的参数之一。 它告诉 DD 您希望 CLIP 在每个时间步骤向您的“提示”移动的强度。通常越高越好,但如果 CGS 太强,则会超出目标并扭曲图像。所以需要一个恰当的中间值,这通常没有统一定式且随每张图像不同需要自己摸索调整。
请注意,此参数通常随图像尺寸缩放。换句话说,如果您将总尺寸增加 50%(例如,从 512 x 512 更改为 512 x 768),那么为了在图像上保持相同的效果,您需要将 clip_guidance_scale 从 5000 增加到 7500。
基本设置中,clip_guidance_scale、steps 和 skip_steps 是影响画质最重要的因素,值得你认真研究一番。
tv_scale: (0|0-1000) 总方差去噪。可选选项,设置为 0 以关闭。 控制最终输出图像色块的“平滑度”。 如果使用,tv_scale 将尝试平滑您的最终图像以减少整体噪声。如果您的图像太“脆”,请增加 tv_scale。 TV denoising (总方差去噪)擅长保留边缘信息的同时消除平坦区域内的噪声。详见 https://en.wikipedia.org/wiki/Total_variation_denoising
range_scale:(150|0-1000)可选选项,设置为 0 以关闭。用于调整颜色对比度。较低的 range_scale 将增加对比度。非常低的 range_scale 会创建减少的调色板,从而产生更鲜艳或类似海报的图像。 更高的 range_scale 会降低对比度,以获得更柔和的图像。
sat_scale:(0|0-20000)饱和度。可选选项,设置为 0 以关闭。如果使用, sat_scale 将有助于减轻过饱和。如果您的图像太饱和,请增加 sat_scale 以降低饱和度。
init_image:可选选项。在上面的图像序列中,显示的第一张图像只是随机噪声。但如果提供了 init_image,则扩散将以 init_image 作为其起始状态来替换随机噪声。要使用 init_image,请将图像上传到 Colab 实例或您的 Google 云端硬盘,并在此处输入完整的图像路径。
如果使用 init_image,您可能需要将 skip_steps 增加到总迭代步数的 50% 左右以保留 init 的特征。有关进一步的讨论请参见上面的 skip_steps 参数介绍。
init_scale: (1000|10-20000) 负责控制 CLIP 尝试匹配提供的 init_image 的强度。(译者注:类似于 init_image 在扩散过程中的权重)这与上面的 clip_guidance_scale (CGS) 相平衡。 init_scale 太大,图像在扩散过程中不会发生太大变化。 而 CGS 太大,init_image 信息会丢失。
cutn_batches:(4|1-8) 每次迭代,AI 将图像切割为一个个小的图像块,称之为切片。并将每个切片与“提示”进行比较,以决定如何指导下一个扩散步骤。更多的切片通常可以产生更好的图像,因为 DD 在每个时间步有更多的机会微调图像精度。
然而,生成额外的切片是内存密集型的操作,如果 DD 试图一次评估太多的切片,它可能会耗尽内存。您可以使用 cutn_batches 来增加每个时间步的切片而不增加内存使用量。
在默认设置下,DD 计划在每个时间步执行 16 次切割。如果 cutn_batches 设置为 1,则每个时间步实际上总共只有 16 次切割。
但是,如果 cutn_batches 增加到 4,DD 将在每个时间步总共进行了 64 次切割,分为 4 个连续批次,每批 16 次切割。因为一次只评估 16 个切片,DD 只使用 16 个剪辑所需的内存,但为您提供 64 个切片的质量优势。当然,那同样意味着渲染每个图像需要大约 4 倍的时间。
因此,(DD的计划切片数)x(cutn_batches)=(每个时间步的总剪切数)。但是,增加 cutn_batches 会增加渲染时间,因为工作是按顺序完成的。 DD 的默认剪辑时间表是一个不错的参考,但剪辑时间表可以在 Cutn Scheduling 部分进行调整,如下所述。
skip_augs:作为其代码的一部分,DD 采用了“torchvision 增强”,在图像创建过程中引入随机图像缩放、透视和其他选择性调整。这些增强原本是想帮助提高图像质量,但可能对边缘产生您不想要的“平滑”效果。通过将 skip_augs 设置为 true,您可以跳过这些增强并稍微加快渲染速度。 建议您尝试使用此设置以了解它如何影响您的项目。
运行设置
当你准备好“提示”和基本设置后,就可以进一步来看看 Do the Run! 单元格附近的代码单元啦!
n_batches: (50|1-100) 此变量设置您希望 DD 创建的静止图像的数量。 如果您使用动画模式(详见下文),DD 将忽略 n_batches 并根据动画设置创建一组动画帧。
display_rate: (50|5-500) 在DD运行期间,您可以使用此变量监控正在创建的每个图像的进度。如果 display_rate 设置为 50,DD 将在每 50 个迭代完成时显示一次进行中的图像。
将此值设置为较低的值,例如 5 或 10,是尽早了解图像前进方向的好方法。如果您不喜欢当前进度,只需中断执行,更改一些设置,然后重新运行。如果您觉得无所谓,也可以将 display_rate 设置为等于 steps,因为显示中间图像确实会稍微降低 Colab 的速度。
resume_run:如果您的运行被中断(例如您自己终止了进程,或者因为断开连接),您可以使用此复选框从中断的地方恢复您的批处理运行。但是,您不得更改批处理中的设置,否则无法可靠地恢复。 其他参数(run_to_resume、resume_from_frame、retain_overwritten_frames)控制您希望如何恢复该次运行。
如果您中断了运行并调整了设置,则不应使用 resume_run,因为这将被视为使用新设置的新运行。
工作流程
一个常见的 DD 工作流程如下:
-
更改“提示”和相关设置
-
进行短期运行
-
评估图像、调整设置
-
再次执行
DD 的生成很难预测,并且图像需要时间来渲染,反馈往往不是即时的。因此,花费时间严谨地记录您所做的更改及其影响是很有必要的。
当您尝试使用文本提示词时,最好减少总步数,以便您可以快速查看提示的效果。一旦您确定了您中意的文本提示词,您就可以进一步调整设置以获得所需的图像质量。
参数研究 – EZ Charts
一些 DD 用户创建了关于扩散参数影响的视觉研究,我们将其中的一些编译到了一个名为 的视觉库中。当您开始考虑如何调整图像时,这是了解参数行为方式的好地方。结尾的资源部分列出了其他参数和艺术家研究。
“设置”文件
为了帮助您跟踪,DD 为每次运行会创建一个“设置”文本文件,存储在批处理文件夹中。这是学习和保存效果良好的设置的绝佳资源。 如果您无法识别报告中的参数名称(并且本指南中未提及),则它可能是您可以忽略的系统变量。
内存管理
在您的 DD 之旅的早期,您常常会看到 “Colab 将耗尽内存”、以及可怕的“ CUDA 内存不足”的系统消息。 这意味着你要求 DD 做一些超出可用 GPU 内存资源的事情。内存不足的常见原因有:
-
试图制作太大的图像
-
试图一次做太多的切割。有关更多信息请参见上文的 cutn_batches 和下文的 Cutn Scheduling
-
试图同时使用太多的 CLIP 或 Diffusion 模型,ViTL/14 和 RN50x64 型号通常需要最多的显卡内存如果您遇到 OOM 报错,只需编辑您的设置并重新运行您的项目。您可也可以试试“重新启动并运行所有”来解决问题
-
在算例不足的 Colab 系统上运行,Colab 的可用 GPU 内存也是随机分配的免费帐户只能获得较低等级的系统,而 Pro 和 Pro+ 用户可以访问更强大的系统。DD 需要启用 GPU 的 Colab 才能正常工作,有时免费层帐户将没有任何可用的 GPU 额度,发生这种情况时难免让人沮丧,但能做的只有等待再次获得额度
DD jupyter 文件的顶部有一个“检查 GPU 状态”的功能,可以显示当前给您分配的系统类型。截至本指南完成时,在 Colab 中,GPU 的能力从最低到最高:
K80 / T4 / P100 / V100 / A100
A100是相当罕见的性能怪兽。如果您刷到了一个,请务必截屏并分享 Discord 以向您的朋友展示(?)(译者注:gacha模式是吧.jpg)
我想在我的超级牛逼的家用电脑上使用运行 DD怎么办?
DD 是在 Google Colab 环境中运行的,使用的是大型 GPU,因此这是本指南的重点。我知道有些人已经成功地在包括他们自己的家用 PC 在内的其他硬件上运行 DD,但我对此一无所知。因此,我无法给出指南。
如果感兴趣的话,查看资源列表以获取有关在 Colab 之外运行 DD 的一些信息的链接,也可以访问 #tech-support 或 #dev 频道与其他人讨论这些问题。
一些别的小问题
如果 DD 由于 OOM 以外的其他原因崩溃:
-
心态放平。这是免费的实验性 AI 代码,发生异常是很有可能的
-
试试去拿一份原始笔记本的新副本来使用。您可能无意中修改了一些关键代码
-
访问 #tech-support 求助
基本部分结束!
至此基础知识的讲解已经结束,恭喜你已经可以独立进行基本的 AI 图像创作啦!