
小刚玩Midjourney 之前玩过一段时间的 Stable Diffusion,个人感觉MJ的优势在于入门容易,只需要提示词就可以很轻松的生成不错的图片,缺点么那就是费钱,而且现在很难生成比较统一的连续画面。而SD的主要优势在于开源,因为开源会有很多无私的大佬分享自己的模型、插件及脚本等,让SD有了更丰富的扩展。在画面统一性和更像本人方面要比MJ容易实现。而缺点就是入门不太容易,不但需要好的显卡这种硬件需要,还需要借助不同的模型来实现不同的风格,需要学习的东西也比较多。做这教程的目的也是为了能够捡起曾经学过的东西,也希望能更系统的掌握SD,顺便探索下那些之前还未触及的知识,希望能够跟大家共同学习进步!
一、Stable Diffusion 安装要求:
① 操作系统:Windows10以后的系统
② CPU:不做强制性要求
③ 内存:推荐8G以上
④ 显卡:必须是Nvidia的独立显卡,显存最低4G,推荐20系以后;A卡、核显只能用CPU跑
⑤ 整合包推荐放在固态硬盘中,提升模型加载速度
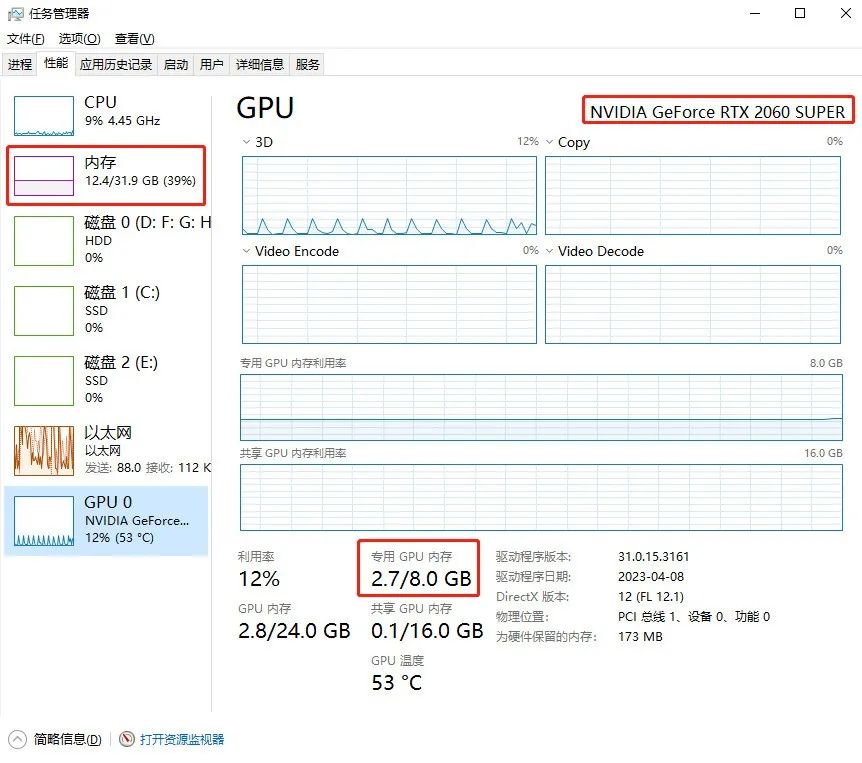
如何查看自己电脑性能:
同时按下 Ctrl+Alt+Delete 三个键(或鼠标右键底下的任务栏),选择任务管理器
二、Stable Diffusion 下载和安装
推荐下载b站秋葉大佬的整合包:
提取码: xgai

安装启动器运行依赖,双击启动器运行依赖一步步安装即可。
解压整合包本体到空间比较大的分区,最好是固定硬盘中,不要安装到中文路径下
解压完后双击启动器就可以运行了,如果开着全局梯子请注意关闭
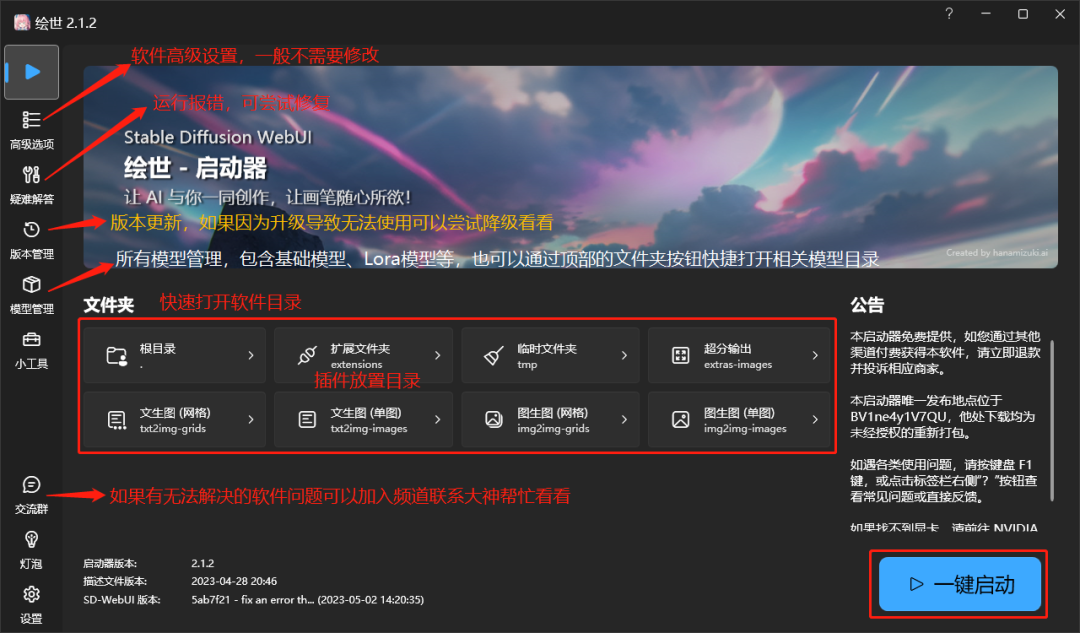
三、通过启动器进入 Stable Diffusion 的 webUi 界面
启动器一览
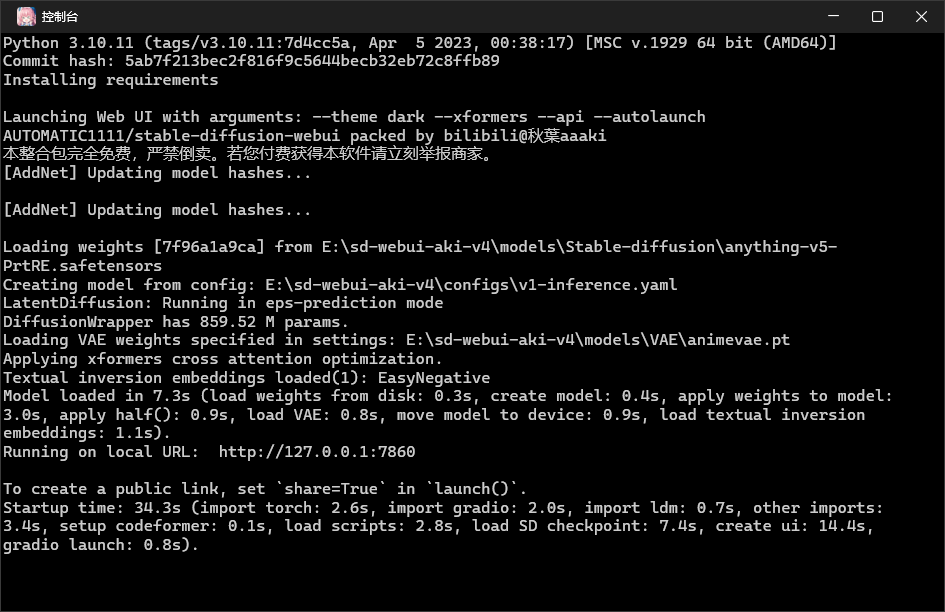
打开启动器,一键启动即可,留意随启动器一起打开的命令窗口,等待一会显示http://127.0.0.1:7860就成功启动了,若启动时有什么报错信息都可以在这个窗口看到,可以尝试用启动器的修复功能先修复看看,如果不行先百度下看看,实在解决不了可以进秋葉大佬的QQ频道咨询一下。
一般会自动打开网页进入绘图页面,文生图最基本的介绍看下图
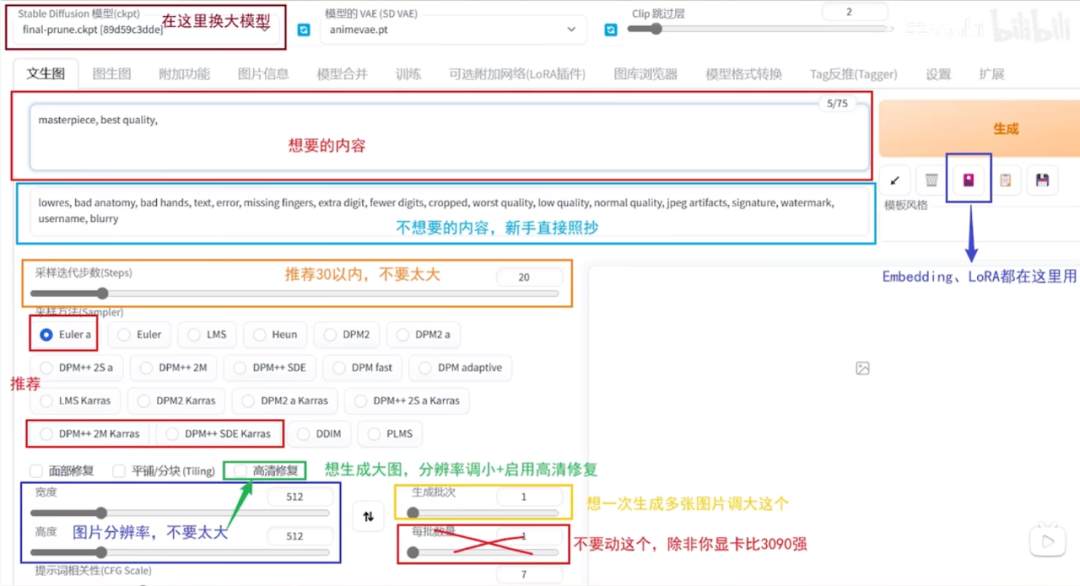
① Stable Diffusion 模型:切换大模型,出什么类型的图主要看这个
② 模型的VAE:VAE模型,主要作用就是滤镜和微调画面,常用的是840000
③ 跳过CLIP层数:数值越小其越贴近模型表现,通常为2不需要动
④ 正向提示词:想要生成的内容
⑤ 反向提示词:画面中不想要的内容
⑥ 迭代步数和采样方法是配套的,生成人物图建议使用DPM++ 2S a采样方法,迭代步数保持在25~30之间。过低过高都不会太好。
⑦ 宽高:一般方图512*512即可,竖图和横图可以保持一边512另一边等比例计算即可,如512*912
⑧ 高清修复:放大处理,想生成大图,分辨率调小+启用高清修复
⑨ 生成批次:一次想生成多少张图片
⑩ 每批数量:一般保持1不要动,极消耗显存
⑪ 提示词引导系数:提示词与画面的相关程度,一般7-10
四、使用提示词生成自己的第一幅 Stable Diffusion 图片
1、正向提示词的内容通常包含人物、场景、环境、视角以及画面品质和画风等基本元素组成



2、提示词的权重,想突出或减弱的画面内容可以使用提示词权重来控制,推荐直接使用小括号:数字的组合,高于1是增加权重,低于1是减少权重,如:
增加权重:(white flower:1.5) 会增加白色的花在画面中出现的概率和画面占比
减少权重:(white flower:0.5) 会减少白色的花在画面中出现的概率和画面占比

3、反向提示词:通常是放不希望出现在画面中的内容,好比描写下雨的场景AI总会把伞画进去,此时就可以把伞相关的词放入这里。反向提示词通常是可以直接抄作业的。如下面这个画人时通常使用的模板:
NSFW, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((grayscale)), skin spots, acnes, skin blemishes, age spot, (ugly:1.331), (duplicate:1.331), (morbid:1.21), (mutilated:1.21), (tranny:1.331), mutated hands, (poorly drawn hands:1.5), blurry, (bad anatomy:1.21), (bad proportions:1.331), extra limbs, (disfigured:1.331), (missing arms:1.331), (extra legs:1.331), (fused fingers:1.61051), (too many fingers:1.61051), (unclear eyes:1.331), lowers, bad hands, missing fingers, extra digit,bad hands, missing fingers, (((extra arms and legs))),
4、如何来写提示词:因为SD对中文的识别不太友好,所以也是需要输入英文提示词来生成画面,这里提供3种方法供参考。
① 翻译大法:使用翻译软件把中文提示词翻译成英文,常用工具有DeepL、谷歌翻译、百度翻译等
② 提示词生成工具:用一些提示词生成工具可以依次选择需要的词,然后直接拷贝进去即可。常用的工具有:
词图:https://www.prompttool.com/NovelAI
AI词汇加速器:https://ai.dawnmark.cn/
promptoMANIA:https://promptomania.com/stable-diffusion-prompt-builder/
③ 直接抄作业:很多网站提供了预览图和完整的提示词,可以直接拷贝过来用,当然要想出跟提示词相似的图片还要留意下使用的基础模型、Lora模型及采样步数等相关参数。相关网站有:
大名鼎鼎的C站:https://civitai.com/(现在这个网站需要梯子才能打开了,这也是主要的模型下载站,模型下面除了模型作者的演示图也会有网友创作的图,大多带有提示词可以参照)
Lexica:https://lexica.art/(虽然图库是他自家的模型,但是提示词一样很有参考价值)
5、生成第一张图吧
正向提示词我们就用:1girl, long hair, long skirt, indoors, morning, upper body, best quality, 8k
反向提示词就用上面给到的,分别填写到对应的输入框,生成自己的第一张图吧。其他参数也可以参考下图设置
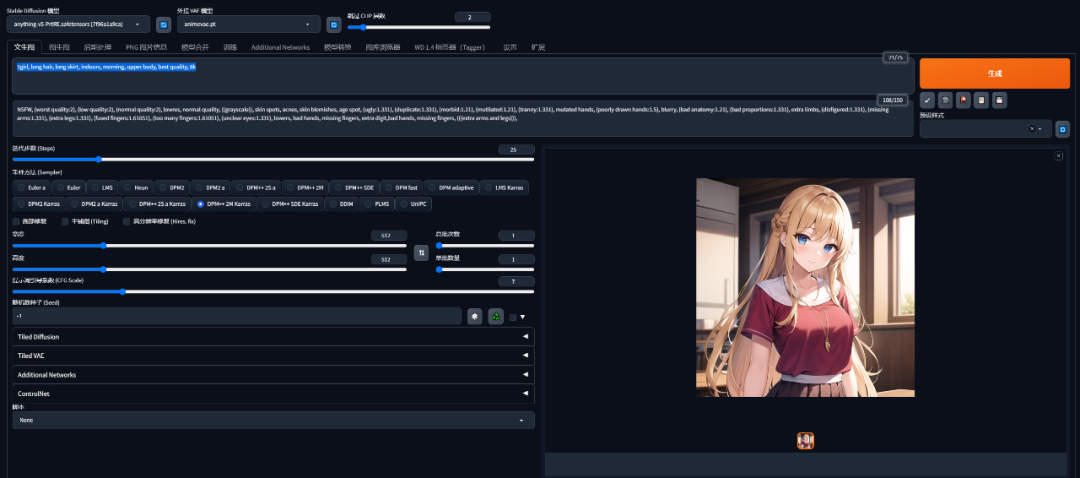
可以把总批次设置成4就可以一次生成4张图片了

好像还不错?但是为啥生成的都是动漫风格的呢?那是因为我们默认使用的是anyting这个大模型主要就是生成动漫风格的。而Stable Diffusion非常依赖模型来生成不同的风格。那么下面就让我们看看怎么更换模型吧。
五、更换 Stable Diffusion 大模型和 LoRA 模型
模型网站通常有下面两个
① C站:https://civitai.com/
全世界最受欢迎的AI绘画模型分享网站,除了模型还有很多优秀作品展示
② 抱脸:https://huggingface.co/models
深度学习和人工智能的专业网站,大佬多,但找起来不是很直观
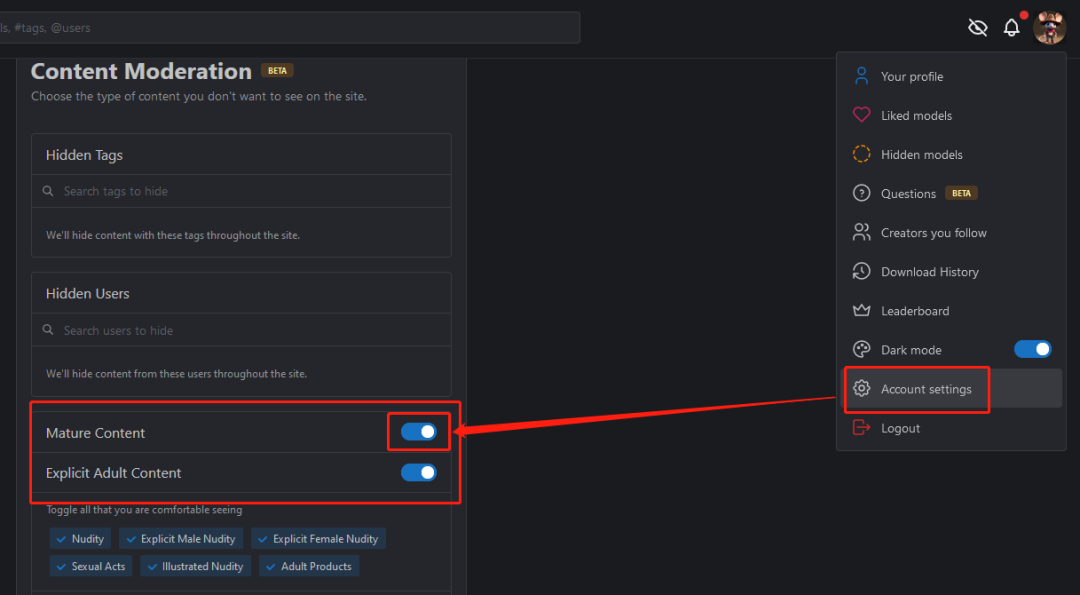
下面以C站为例说下如何下载,需要梯子,建议注册登录下账户,如果新账户可以点击头像在“Account settings”-“Mature Content”选项打开(如果你已满18周岁)就可以看到更多的模型了
一般我们使用最多的模型分两种,一种是大模型,一种是LoRA模型。
大模型:经过训练的图片合集,被称作模型,也就是chekpoint,体积较大,一般真人版的单个模型的大小在7GB左右,动漫版的在2-5个G之间。早期的CKPT后缀名是ckpt,如今新的CKPT后缀名都是safetensors
LoRA模型:是一种体积较小的绘画模型,是对大模型的微调。与每次作画只能选择一个大模型不同,lora模型可以在已选择大模型的基础上添加一个甚至多个。一般体积在几十到几百兆左右。后缀也是safetensors
如下图:CHECKPOINT就是大模型;LORA就是微调模型

下面让我们在C站先选一个写实一点的大模型,可以在右侧的筛选器选为所有时间。
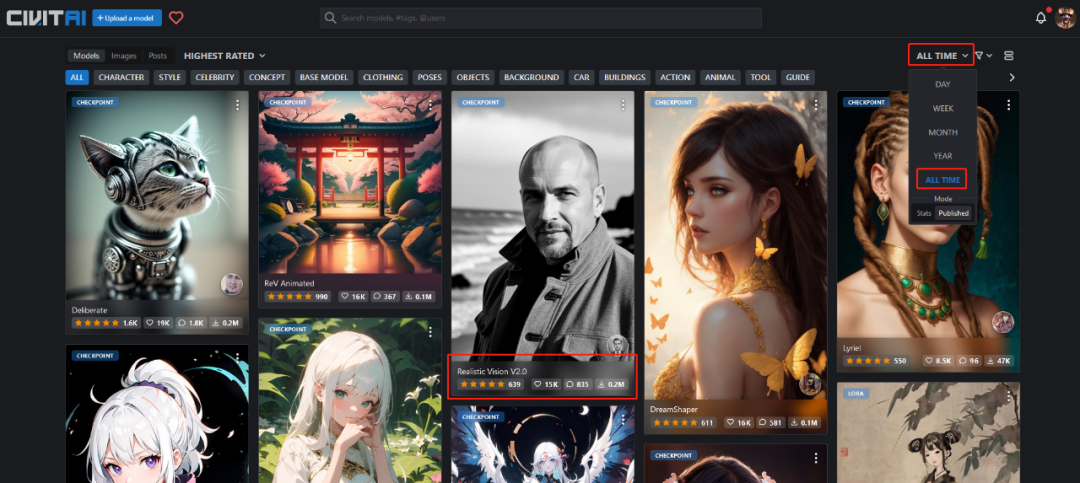
然后选择一个 Realistic Vision V2.0 点开,可以看到这么模型基本2G,可以用迅雷等下载工具下载
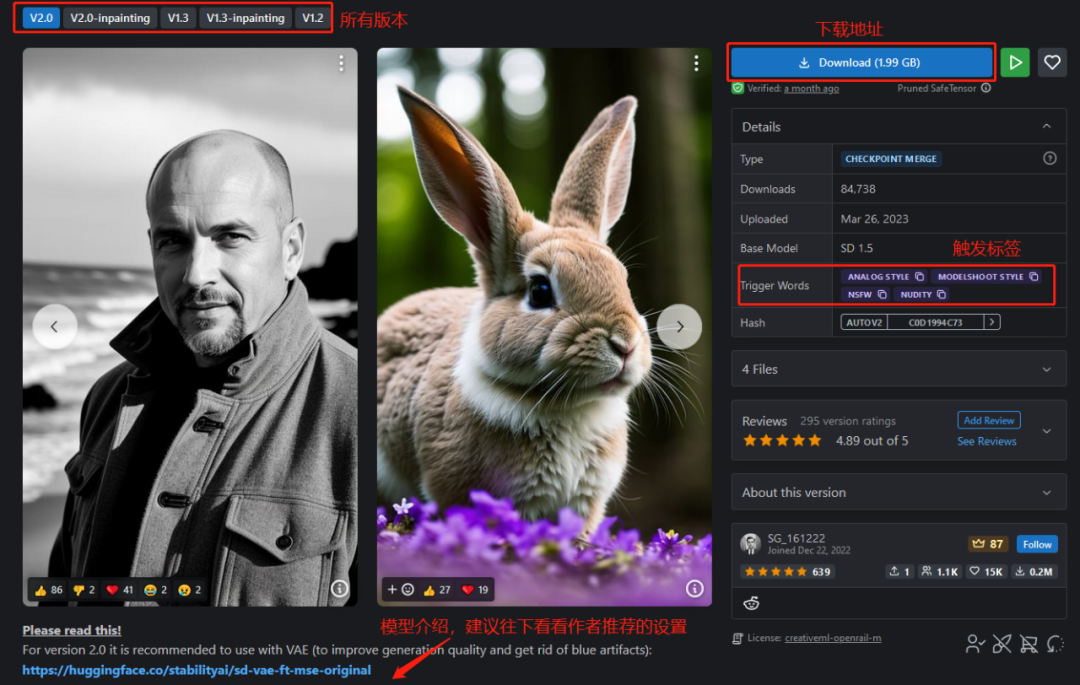
下载完成后,我们把文件放到绘画软件下的 modelsStable-diffusion 文件夹中,也可以在启动器模型里面快捷打开文件夹
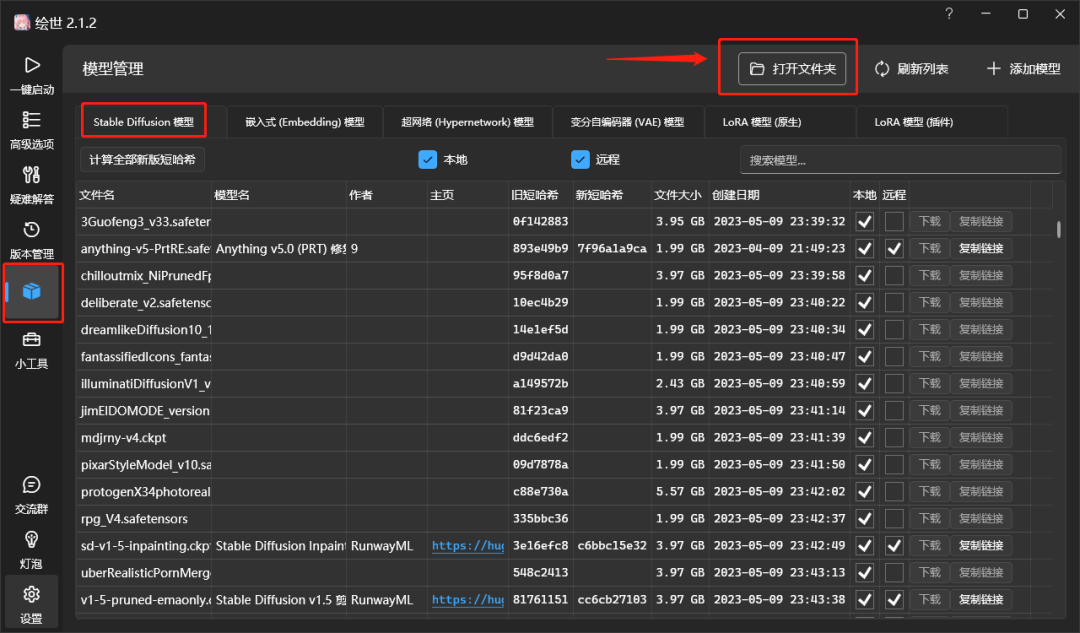
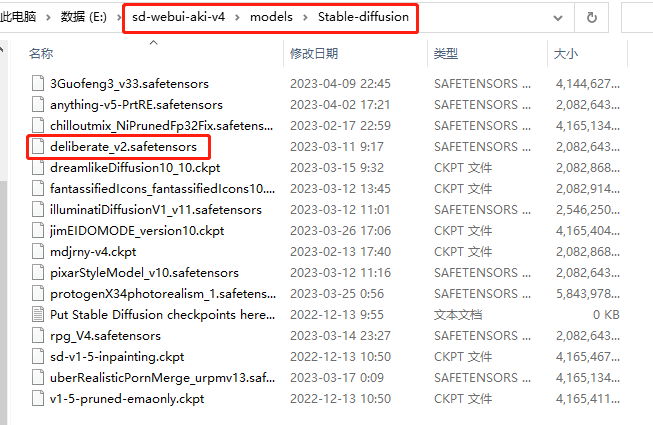
然后回到web页面,点击左上角大模型旁边的刷新按钮就可以看到了,外挂VAE也建议选成840000这个

然后我们用同样的提示词生成看看

可以看到风格确实变了,但是这生成的是什么。。。一般这种情况如果不是模型的问题那就是提示词的问题了,感觉是long skirt会让景别更大更会生成全身像的图,让我们把提示词稍微改改加上beauty face,close-up这些提示词试试:1girl, beauty face, long hair, close-up, long skirt, indoors, morning, upper body, best quality, 8k,

这次生成的还说的过去了,另外我们也可以看看模型简介,有些作者会有推荐的建议。
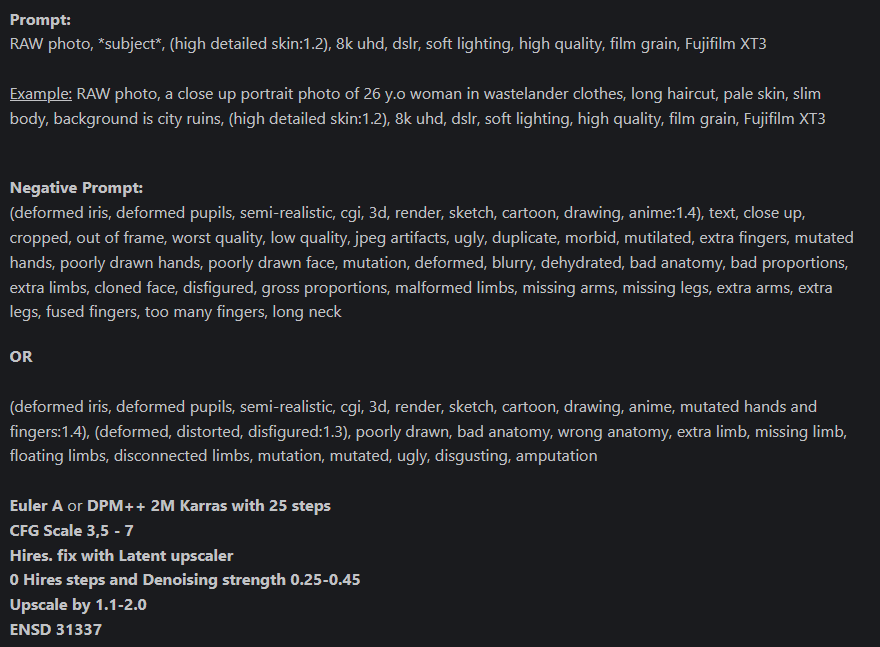
然后我们按照建议修改一下提示词:RAW photo, 1girl, beauty face, long hair, long skirt,, (high detailed skin:1.2), 8k uhd, dslr, soft lighting, high quality, film grain, Fujifilm XT3
把反向提示词和相关参数也修改一下,然后出图效果

然后让我们看看LoRA模型可以干什么,可以在查找时直接筛选LoRA,然后我们找到一个比较东方一些的面孔,我们下载LoRA模型时候主要留意下Trigger Words 这一项,这是触发此LoRA的主要提示词
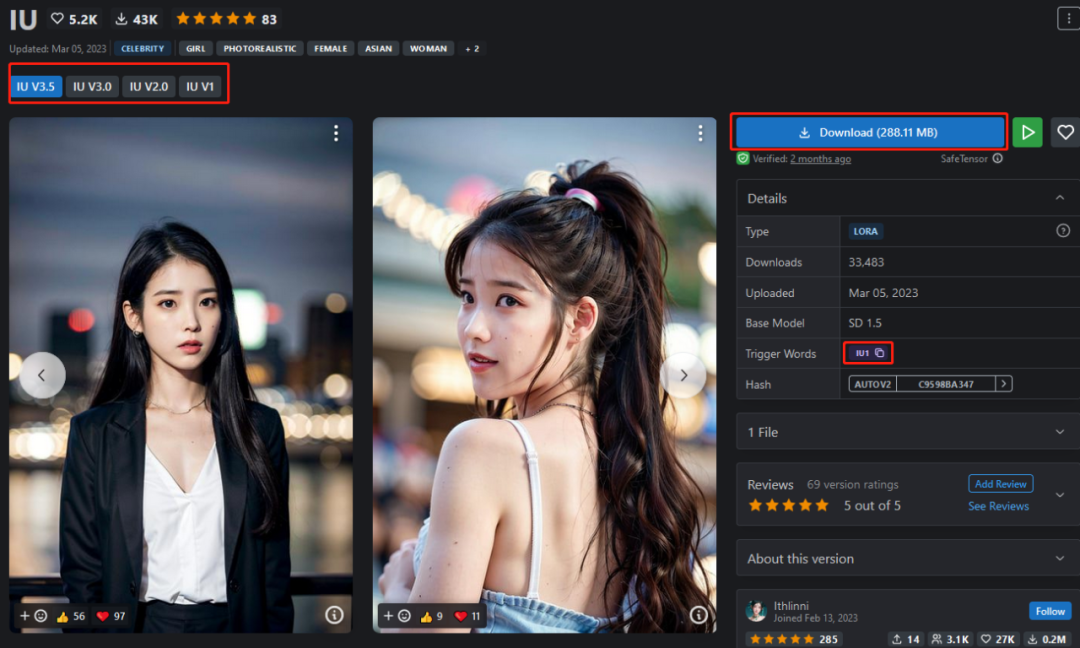
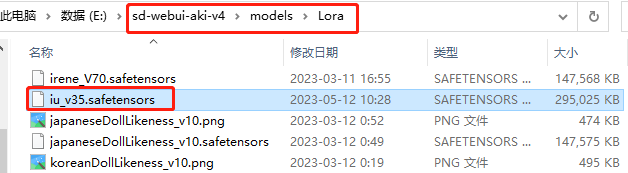
LoRA模型下载好了要放到modelsLora模型目录下
然后点击生成按钮下面的“显示/隐藏扩展模型”按钮,点到LoRA标签,就会显示所有下载的LoRA模型,点击刷新按钮就会显示出来刚下载的模型
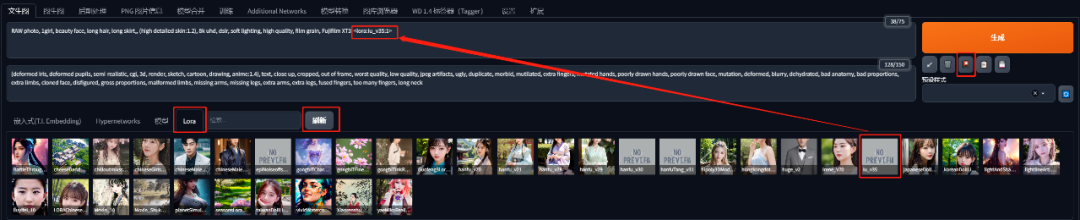
然后我们只要点击下载的LoRA模型就可以把模型调用参数放入正向提示词里面了,如
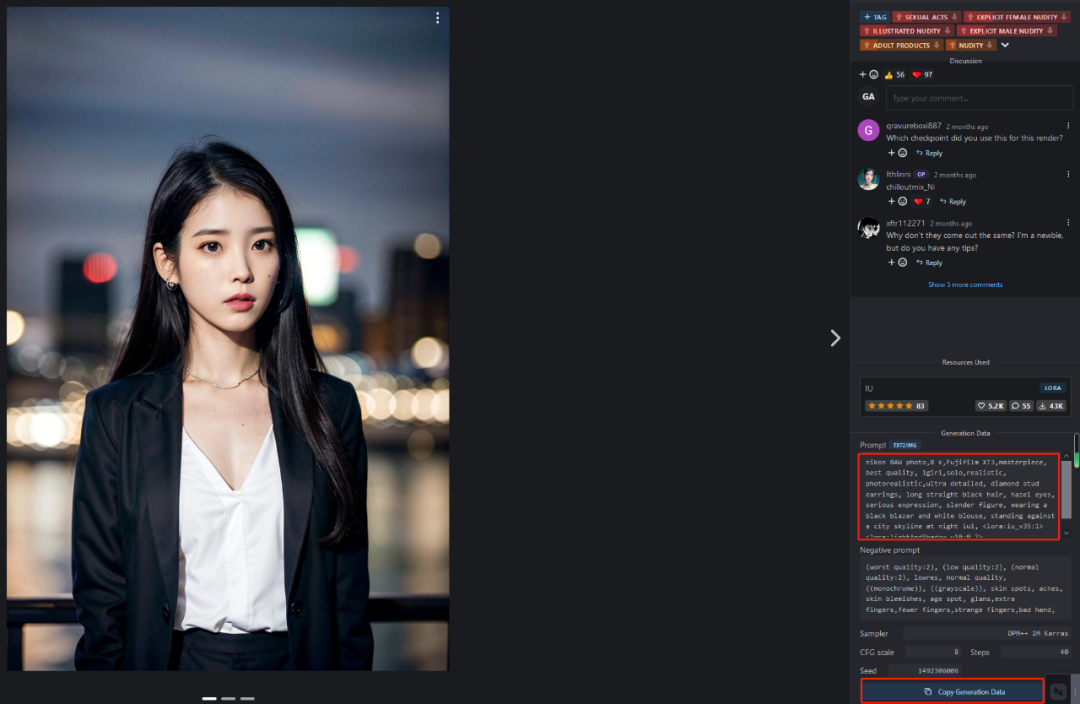
可以看到生成的脸形有些相近了,但是要跟原图更像除了参数更重要的是选择的大模型也最好是相同的。

另外多个LoRA模型是可以混合使用的,下面我们再下载一个汉服的LoRA模型结合使用看看。LoRA模型总权重尽量不要超过1,当然这也不是绝对的。
(8k, best quality, masterpiece:1.2), (realistic, photo-realistic:1.2), 1girl,

为了展示汉服比较高的权重用在full body这个提示词,但这很可能会让生成的图有点崩,(毕竟哪怕是强如Midjourney全身人像和环境都会有点力不从心的感觉)那就可以尝试调高 宽高 给更多的分辨率;或者保持比较小的宽高,开启“高清修复” ,比较推荐后一种方法。
以上就是这节Stable Diffution 的基础入门内容,看完了你就可以下载自己喜欢的模型进行探索了,当然SD会比MJ玩起来更复杂,需要学习的内容也更多。
推荐以下几个B站UP主,最后一位的SD系列教程非常值得一看:
秋葉aaaki:https://space.bilibili.com/12566101
独立研究员-星空:https://space.bilibili.com/250989068
人工治障:https://space.bilibili.com/498518999
小李xiaolxl:https://space.bilibili.com/34590220
Nenly同学:https://space.bilibili.com/1814756990