
AUTOMATIC1111 Stable Diffusion WebUI 更新了1.6版本,下面看看都更新了那些内容
WebUi项目地址:https://github.com/AUTOMATIC1111/stable-diffusion-webui
主要更新:
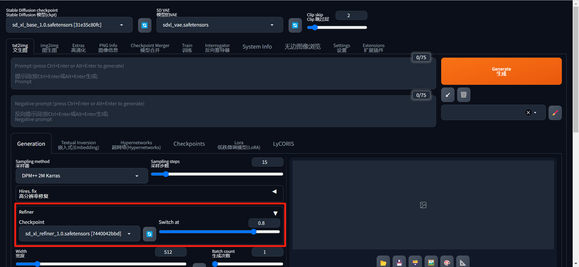
1、支持单独设置 refiner(细化模型)
Refiner 选项框内包含两个选项,一个是模型的选择框 “checkpoint”,另一个是决定何时开始使用 refiner 模型 “switch at”。当 “switch at”设定为0.5时即表示前一半的步骤使用 base 模型迭代,最后一半的步骤使用 refiner 模型迭代。设定为1则表示关闭此功能。
很有意思的是,refiner 的模型选项框内可以选择不止refiner 模型,还可以选择其他的普通模型(SDXL 和 SD1.5 都可以),因此就衍生出一种新的玩法(虽然这在 ComfyUI 中算是常见用法),比如前面几步我使用真实模型,后面几步则使用动漫模型推理,生成更具特色的图片。
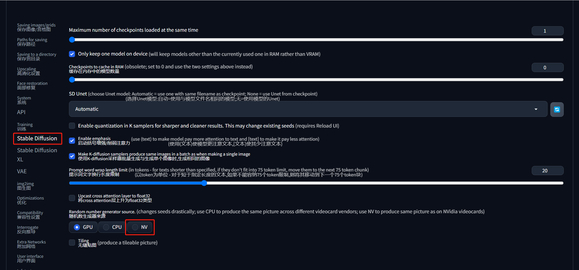
2、新添 NV 选项
在 “设置 > stable diffusion > 随机数生成器来源” 选项中新添了第三个选项 “NV”。选择 NV 后就可以保证在不同设备中生成的图片都能与使用N卡生成的效果保持一致。所以,如果你想保证相同参数设置下能生成一样的图片,则可以勾选此选项。
3、新增风格编辑对话框
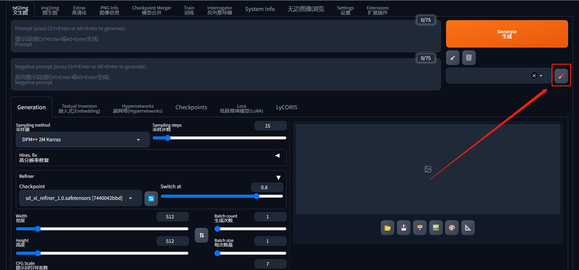
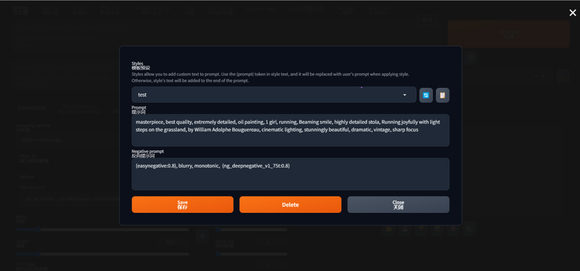
点击该图标后,会弹出如下对话框,在其中增添、删除或编辑风格。这是新增的功能,以前只能保存,不能直接删改,现在方便很多。
4、高清修复可以选择不同的模型了
勾选 “设置 > 用户界面 > Hires.fix: show hires checkpoint and sampler selection ” 选项,即可开启此功能。顺便可以勾选该选项下面的选项,还可以针对高清修复过程使用不同的提示词。
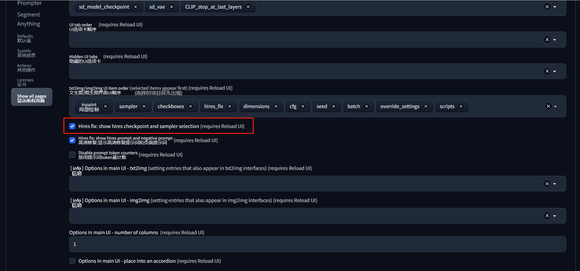
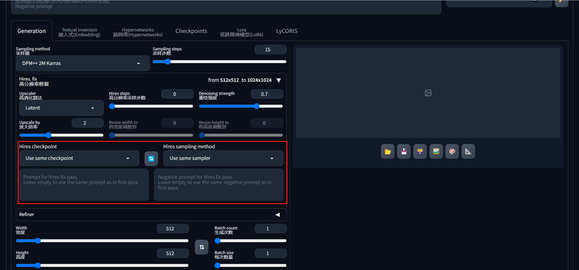
开启后就可以在 Hires.fix 选项框中选择使用不同的模型和采样器来完成高清修复过程。
5、新增加载多个模型到内存功能
在默认设置下,使用 SDXL 跑图一般会先加载 base 模型并利用 base 模型进行前几步的迭代,然后 webui 会将 base 模型从内存卸载,再加载 refiner 模型进行后续步骤的迭代。如果你的内存不足,这是一个无奈的选择,但如果你的内存足够,则可以将 base 和 refiner 模型都加载到内存,避免了每次生图都要重新加载的问题,从而加快生成速度。
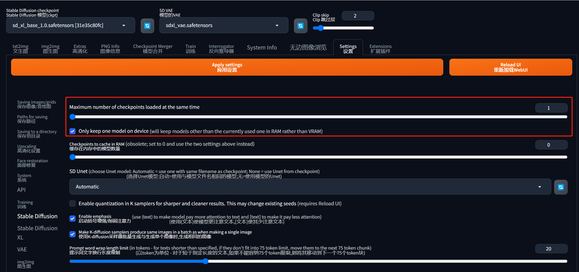
如果想使用此功能,则需要在 “设置 > stable diffusion > Maximum number of checkpoints loaded at the same time” 中选择同时加载模型的最大数量,要大于1,并将 Only keep one model on device 的勾选去掉。如果你的内存足够,可以适当提高加载模型的最大数量。
6、新增多种采样方法
这些方法包括:Restart, DPM++ 2M SDE Exponential, DPM++ 2M SDE Heun, DPM++ 2M SDE Heun Karras, DPM++ 2M SDE Heun Exponential, DPM++ 3M SDE, DPM++ 3M SDE Karras, DPM++ 3M SDE Exponential。

据说是比较高效的采样方法,但更多具体细节还有待进一步测试。
7、对 DDIM, PLMS, UniPC 采样方法进行返工使之可以适用于 SDXL
8、把 extra network 选项单独拎出来了
extra network 作为一个非常常用的功能,现在可以在主页面直接选择,方便我们选择 lora和embedding 等等。
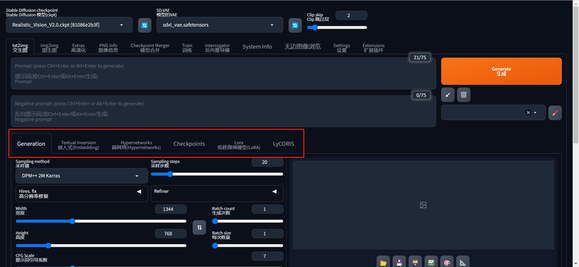
9、优化了加载模型的内存占用,将会使用更少的内存,低内存用户福音。
10、新增对 SDXL 嵌入的支持
现在可以使用 SDXL 的 embedding(嵌入)了
11、在 extra network UI 的 checkpoint 中添加模型元数据选项
点按上面扳手图标将会弹出下面的对话框,可以在其中给每个模型添加备注,以及选择不同的默认外挂 VAE 模型。
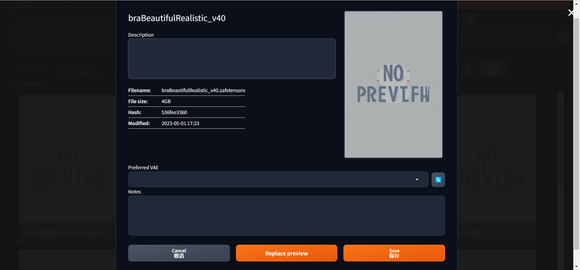
添加后的效果示例如下。
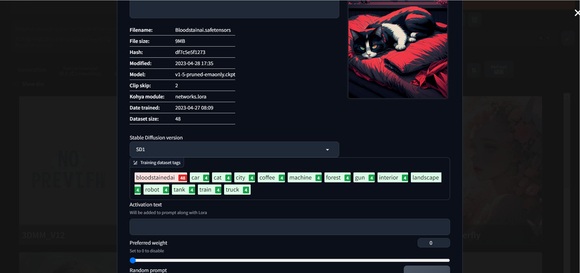
lora 的元数据还包括了训练所使用的 tags,除此之外还可以做更多更改,如下图所示。
12、新增在提示词的数字后面添加空格的支持
强迫症患者福音。可能好些人在写提示词的时候为了美观,都会在每个单词或数字前后添加一个空格,比如 [ red : green : 0.5 ],这在之前的版本中,如果该数字后面存在空格会导致该提示词失效,更新之后这个问题被解决了。
13、可以为每个模型选择不同的默认 VAE 模型,需要在模型的元数据中更改,参看第11条内容
14、将文生图和图生图的界面设置分开以方便单独设置
在 “设置 > 用户界面”,使用鼠标滚轮拉到最下面即可看到新增的选型。
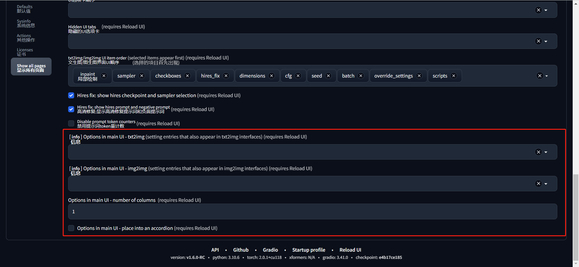
版本更新后,如果你发现你找不到脸部修复的选项了,那么就需要在这个设置中,将该 face restoration 添加进去,并建议勾选最后一个选项 options in main UI,如下图所示。
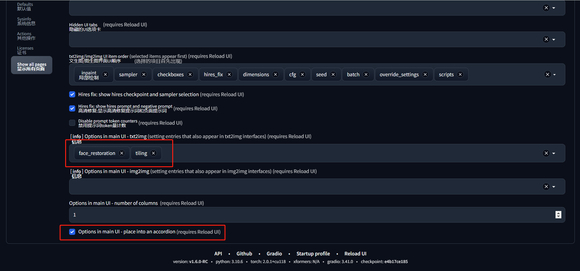
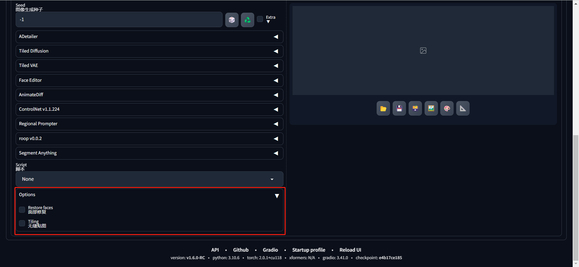
保存设置并重启后,你可以在文生图页面的如下位置找到该选项
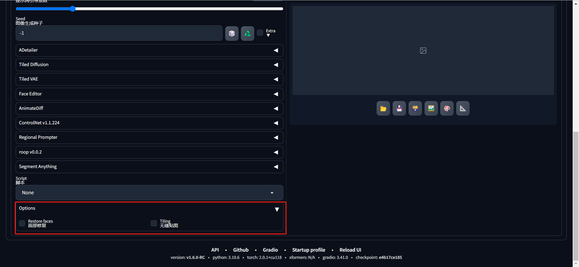
将 number of columns 设置为2,添加的参数则会以两列的方式展示,如下图。
15、可以自由更改参数框和图片框的占比
预览大图更方便啦!
16、新增启动参数 –medvram-sdxl
针对 SDXL 优化的参数设置,可以降低使用 SDXL 生图的过程中模型对显存的占用。小于等于8G显存的显卡建议添加
次要更新:
1、降低图生图批量生成时的内存和显存占用,据测试, batch size 为4,512×512→1024×1024的高清修复的编码阶段,显存峰值占用从超过16G下降到低于8G,改进很明显。仅对批量生成有效。具体效果有待进一步测试。
2、降低图片后处理(postprocessing)和后期处理(extra)的内存占用
3、优化脚本 xyz 图表
4、添加 gradio 版本警告,可能 dradio 版本过低会被提醒
5、现在可以使用透明的白色或其它颜色绘制蒙版了
6、在 extra network 中添加了 show dir(展示路径)选项
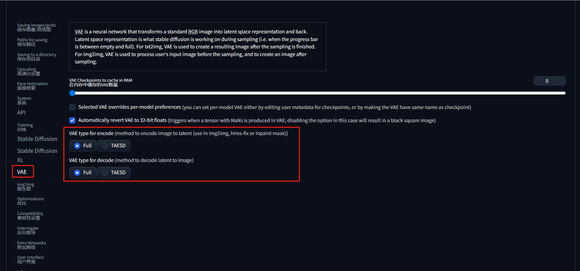
7、新增 TAESD 选项,TAESD 可以被视为一种正常的 VAE,但是会伴随部分质量的损失。不过好处是可以提高生图速度,降低显存占用。在设置 > VAE 中找到编解码图片的 VAE 类型设置。
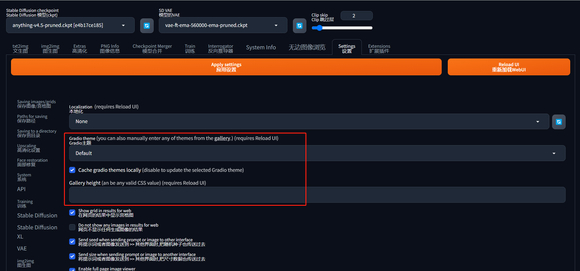
8、添加了缓存主题选项,避免原作者更新主题后,用户界面跟着发生改变。同时还添加了新的主题。
9、新增是否保存不完整图片的选项,默认开启
10、允许使用鼠标中键在新的浏览器页面打开图片(我没测试成功)
11、运行 webui.bat 会自动在浏览器打开了
12、将 DPM++ 2M Karras 采样器设置为默认选项
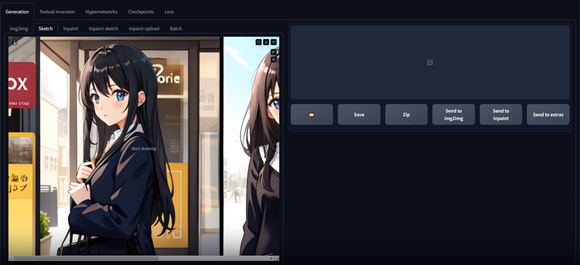
13、上传的图片自动缩放为框大小,使之展示全面
改变前:
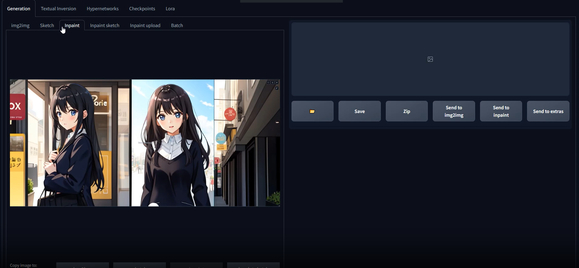
改变后:
14、新增将 lora 缓存在内存中的选项,可避免重复加载,提高生成速度
15、脸部修复和 tiling 需要手动添加一下,详见主要更新的第14条内容
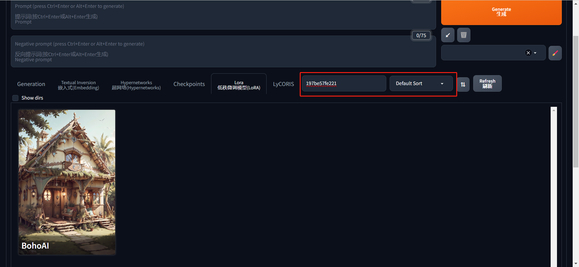
16、为所有 extra network 模型添加 hash 值,可以直接使用 hash 搜索,同时还添加了排序功能。
17、在图生图界面添加了 extra noise 参数选项。需要在 “设置 > 用户界面” 位置添加该参数。
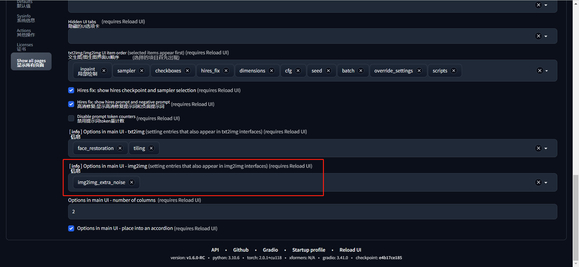
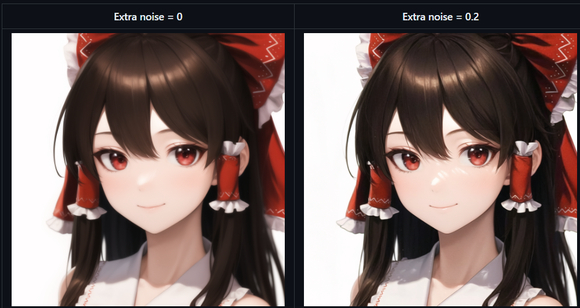
设置 extra noise 前后的区别如下图所示
18、支持具有 bias 的 lora
19、点击中止按钮后,能更快中止生成了
20、优化了图片预览窗口,预览尺寸更大
21、优化控制台进度条,加快更新频率
来源:https://tieba.baidu.com/p/8578570260